Ordered Homogeneity Pursuit Lasso for Group Variable Selection with Applications to Spectroscopic Data
2School of Mathematics and Statistics, Central South University, Changsha 410083, China
3Seven Bridges Genomics, 1 Main Street, Cambridge, MA 02142, USA
*Corresponding author. E-mail: qsxu@csu.edu.cn
Abstract
In high-dimensional data modeling, variable selection methods have been a popular choice to improve the prediction accuracy by effectively selecting the subset of informative variables, and such methods can enhance the model interpretability with sparse representation. In this study, we propose a novel group variable selection method named ordered homogeneity pursuit lasso (OHPL) that takes the homogeneity structure in high-dimensional data into account. OHPL is particularly useful in high-dimensional datasets with strongly correlated variables. We illustrate the approach using three real-world spectroscopic datasets and compare it with four state-of-the-art variable selection methods. The benchmark results on real-world data show that the proposed method is capable of identifying a small number of influential groups and has better prediction performance than its competitors.
Downloads
- Read the paper online
- Download the paper PDF
- Download the datasets
- View the software documentation
Software
Install the R package OHPL from CRAN:
install.packages("OHPL")Or, the latest version from GitHub:
devtools::install_github("nanxstats/OHPL")Citation
BibTeX
@article{Lin2017,
title = "Ordered homogeneity pursuit lasso for group variable selection with applications to spectroscopic data",
author = "You-Wu Lin and Nan Xiao and Li-Li Wang and Chuan-Quan Li and Qing-Song Xu",
journal = "Chemometrics and Intelligent Laboratory Systems",
year = "2017",
volume = "168",
pages = "62--71",
issn = "0169-7439",
doi = "https://doi.org/10.1016/j.chemolab.2017.07.004",
url = "http://www.sciencedirect.com/science/article/pii/S0169743917300503"
}
Datasets

The beer dataset contains 60 samples published by Norgaard et al. Recorded with a 30mm quartz cell on the undiluted degassed beer and measured from 1100 to 2250 nm (576 data points) in steps of 2 nm. Original extract concentration which illustrates the substrate potential for the yeast to ferment alcohol is the property of interest. [Download]

The wheat dataset contains 100 wheat samples with specified protein and moisture content, published by J. Kalivas. Samples were measured by diffuse reflectance as log (I/R) from 1100 to 2500 nm (701 data points) in 2 nm intervals. The protein of wheat is used as the property of interest in our study. [Download]

The soil dataset contains 108 sample measurements from the wavelength range of 400–2500 nm (visible and near infrared spectrum) published by Rinnan et al. We chose 1100–2500 nm range of NIR (700 data points) as the design matrix. Soil organic matter (SOM) is considered as the property of interest. [Download]
The OHPL Algorithm
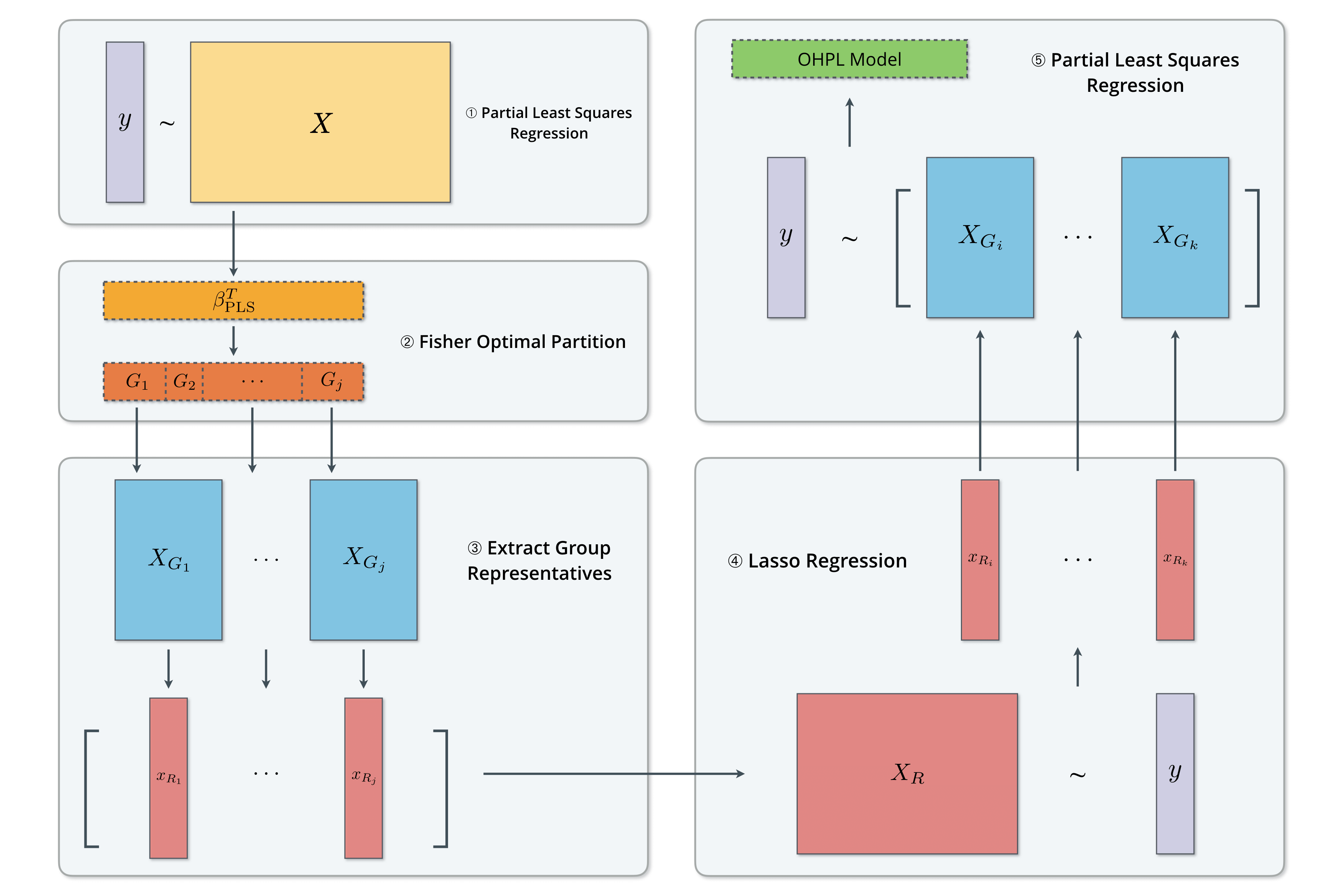
Spectroscopic Data Analysis
The beer dataset
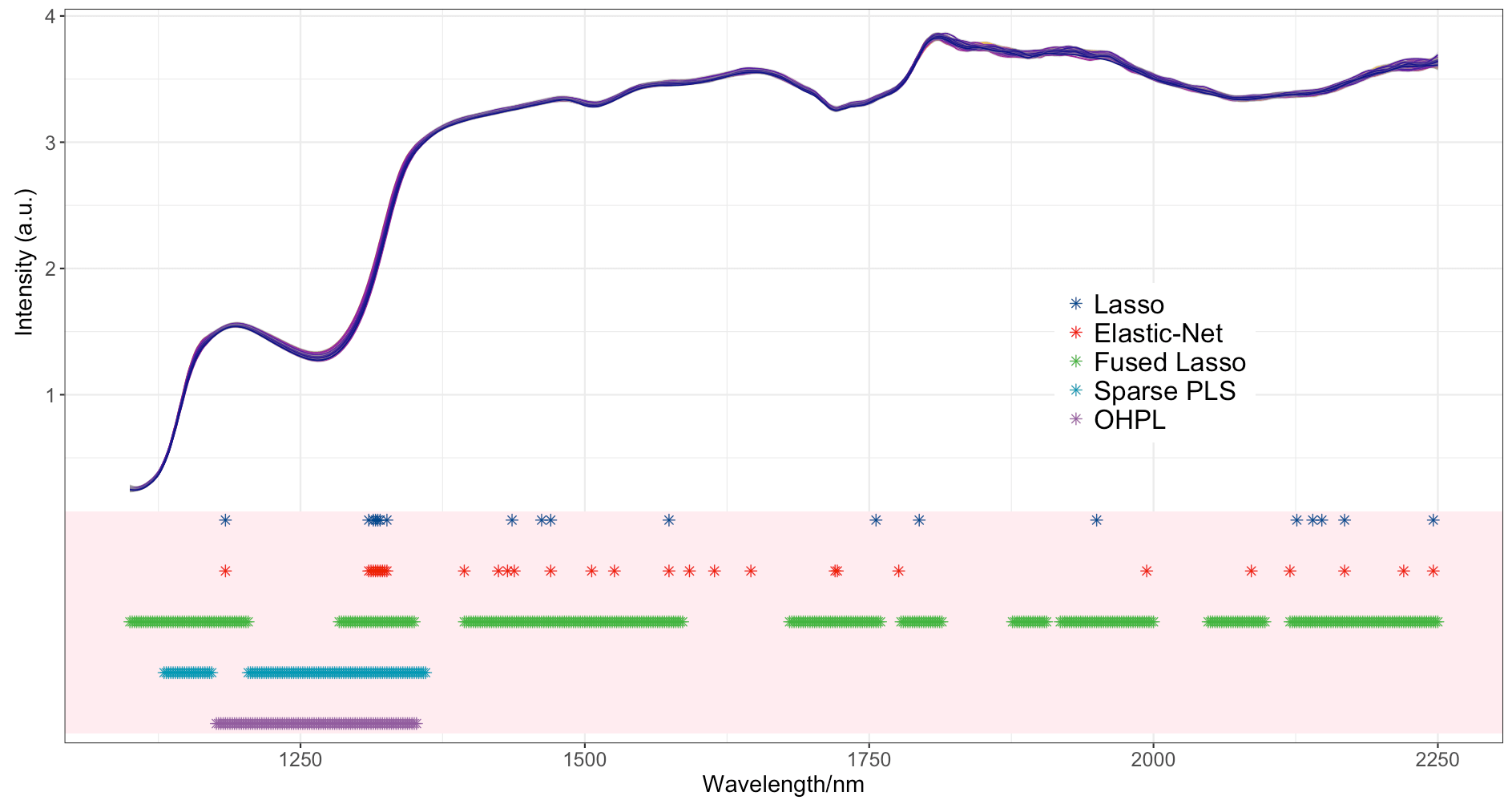
This figure shows the original NIR spectra and the variables selected by different methods for the beer dataset. Fused lasso and Sparse PLS tend to select a larger number of variables, while the nVAR obtained by OHPL, elastic net, and lasso are lower. The group selected by OHPL is the region of 1172–1352 nm, which corresponds to the first overtone of O-H stretching bond vibration.
The wheat dataset
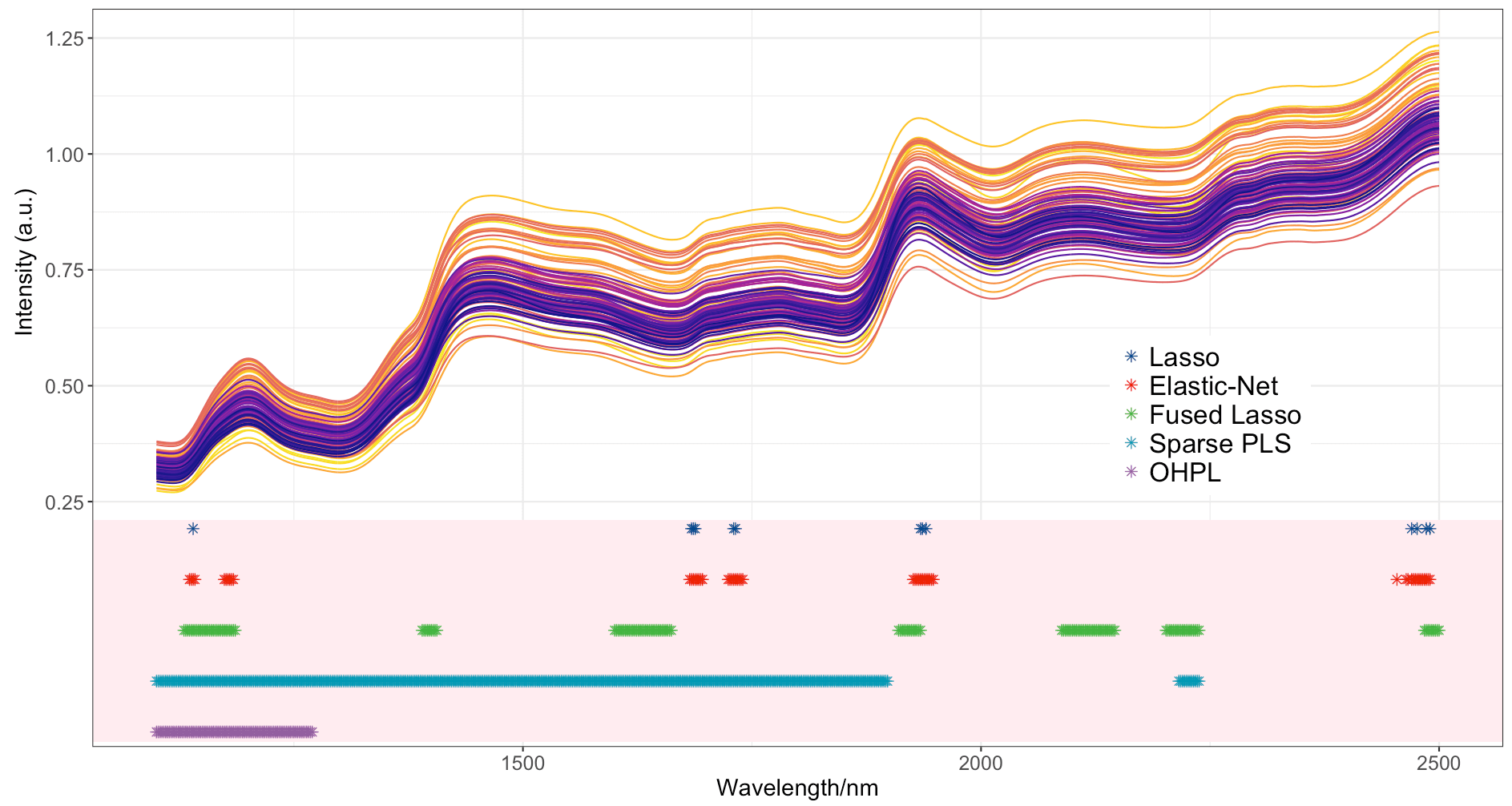
This figure displays the original NIR spectra and the variables selected by the five methods for the wheat dataset. The variables selected by OHPL are located in the region 1100–1300 nm. The selected informative intervals are distributed in a broad region, which, is implicitly in accordance with the complex structure characteristics of protein. This wide region contains the third overtones of C-H groups (850–865 nm), the second overtones of C-H groups (near 888 nm), the second overtones of O-H groups (972–988 nm), the second overtones of N-H groups (near 1012 nm) , and the interactions between them.
The soil dataset
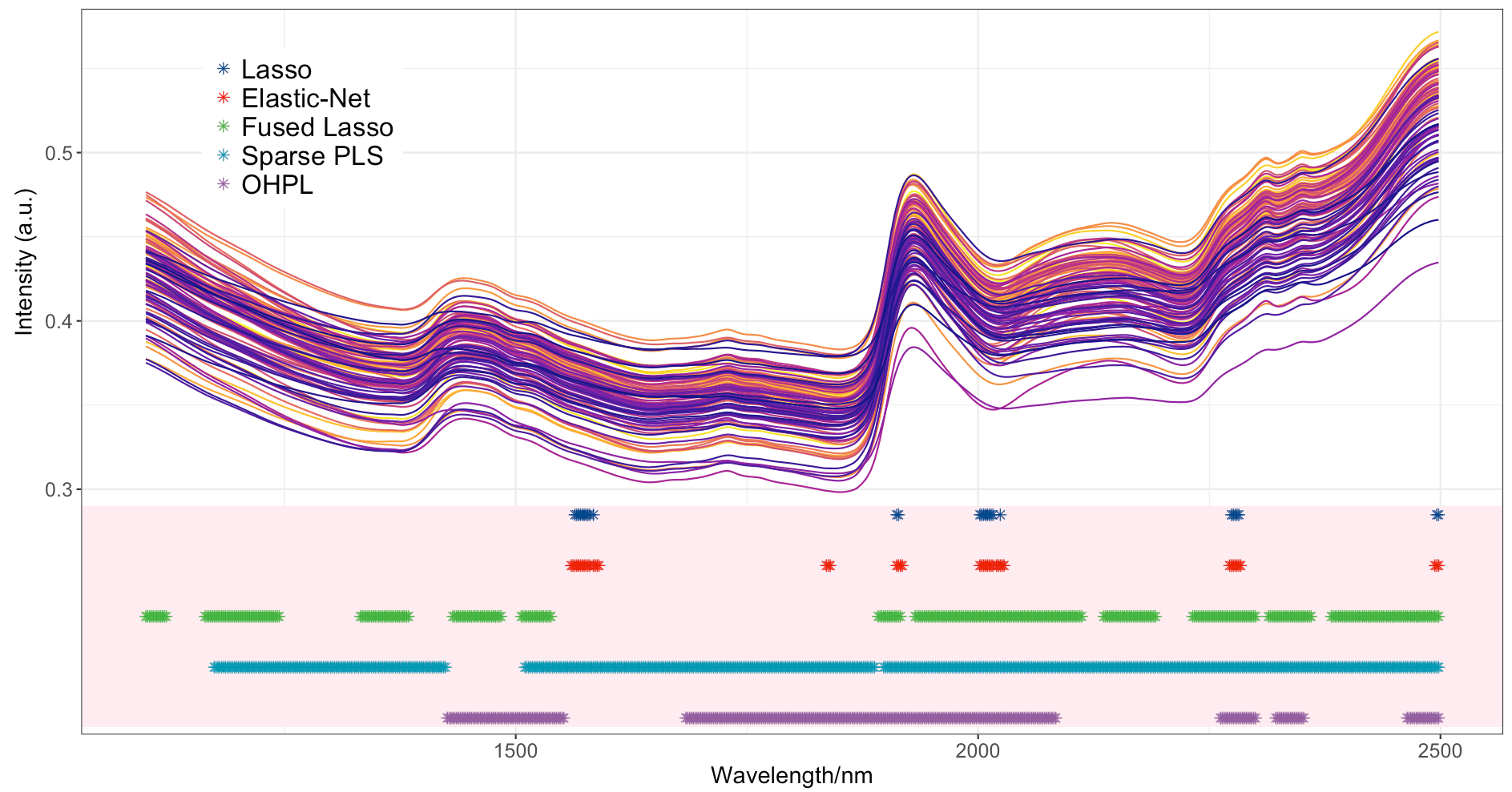
This figure shows the original NIR spectra and the wavelength selection results by the five methods for the soil dataset. The informative spectra regions are near 1420 nm (region 1), 1900–1950 nm (region 2), 2040–2260 nm (region 3), and 2440–2460nm (region 4). Lasso and elastic net failed to select the informative wavelength region 1 and region 3. OHPL selected the regions near 1420–1554 nm, 1686–2086 nm, 2264–2302 nm, 2324–2354 nm, and 2460–2500 nm. All the selected regions correspond to the chemical bond except the region of 2324–2354 nm.